
Today I will show you how to import the Marvel graph into Neo4j. We will use a very simple graph model. I will show you the advantages of having a social network stored in a graph database.
Requirements:
- Neo4j — Neo4j Site
- Apoc plugin — Apoc plugin
Data:
We will use the marvel social network data, which was downloaded from a kaggle competition post. There are 3 CSVs available.
- nodes.csv — Node name and type
- edges.csv — Heroes and the comic in which they appear.
- hero-network.csv — Edges between heroes that appear in the same comic.
We only need the edges.csv file, because if we know which hero appeared in which comic, that is enough for us to import the social graph. We also do not need the hero-network.csv, that hold information about unweighted hero network, because we will create our own weighted hero network with the help of cypher and apoc.
Graph model:
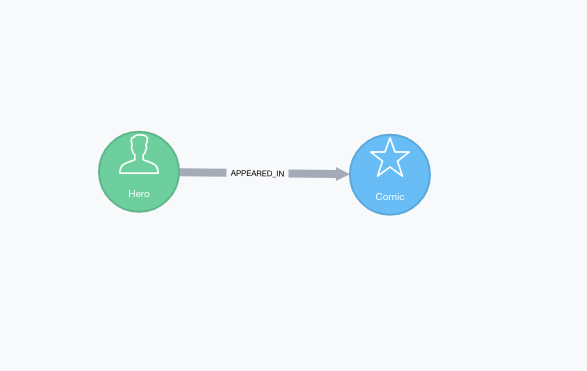
We will use a very simple graph model, with nodes labeled Hero,Comic and a relationship APPEARED_IN between them.
Import:
First we create constraints on labels Comic and Hero, so that our queries will be more optimized and faster.
CALL apoc.schema.assert(
{},
{Comic:['name'],Hero:['name']});
I uploaded the edges.csv to my git repository, so you can import the graph in one step using below query. It it very basic, we just MERGE two nodes and a relationship between them. When we are importing larger amounts of data, we want to batch it with USING PERIODIC COMMIT.
USING PERIODIC COMMIT 5000
LOAD CSV WITH HEADERS FROM
"https://raw.githubusercontent.com/tomasonjo/neo4j-marvel/master/data/edges.csv" as row
MERGE (h:Hero{name:row.hero})
MERGE (c:Comic{name:row.comic})
MERGE (h)-[:APPEARED_IN]->(c)
Create a weighted undirected hero network:
Now that we have imported the data, we will create a weighted hero network, where we will assume, that the more comics hero appeared together, the more they know each other. We will save the number of comics heroes appeared together as a weight property of the KNOWS relationship.
We will use apoc.periodic.iterate to help us with batching. As our graph gets bigger, we do not want run global refactoring or calculations in one transaction, but we want to batch it. Apoc comes in handy when using batching with cypher.
Taken from apoc documentation:
With apoc.periodic.iterate you provide 2 statements, the first outer statement is providing a stream of values to be processed. The second, inner statement processes one element at a time or with iterateList:true the whole batch at a time.
We can use following query to create a weighted undirected hero social graph.
CALL apoc.periodic.iterate(
"MATCH (p1:Hero)-->(:Comic)<--(p2:Hero) where id(p1) < id(p2) RETURN p1,p2",
"MERGE (p1)-[r:KNOWS]-(p2) ON CREATE SET r.weight = 1 ON MATCH SET r.weight = r.weight + 1"
, {batchSize:5000, parallel:false,iterateList:true})
Now lets dissect the query for better understanding.
First outer statement:
First outer statement should return a stream of values to be processed. It consists of a simple cypher query that matches two heroes, that appeared in the same comic. There is a small, but important detail in WHERE id(p1) < id(p2) statement. This way we avoid doubling the results, because with using <> instead of < , MATCH will return every relationship twice, with the first MATCH returning hero1 as p1 and hero2 as p2, and the second MATCH returning hero1 as p2 and hero2 as p1.
MATCH (p1:Hero)-->(:Comic)<--(p2:Hero) where id(p1) < id(p2) RETURN p1,p2
Second inner statement:
The second inner statement processes one element at a time or with iterateList:true the whole batch at a time. We use MERGE to create the relationship. It means that it will try to match the relationship and if it doesn’t find one it will create one. Check docs for more info. Cypher has a built in logic that supports action based on whether the node or the relationship was created or found using MERGE. We can use ON CREATE SET, for scenarios when the node is created or ON MATCH SET, if the node was found(already exists).
We can also notice, that we do not specify the direction of the relationship. We treat this network as undirected, so the direction of relationship has no implication. MERGE provides the ability to not specify direction, which in practice means, that it checks if there is a relationship between given nodes in any direction, and if not found, it creates one in a random direction.
MERGE (p1)-[r:KNOWS]-(p2) ON CREATE SET r.weight = 1 ON MATCH SET r.weight = r.weight + 1
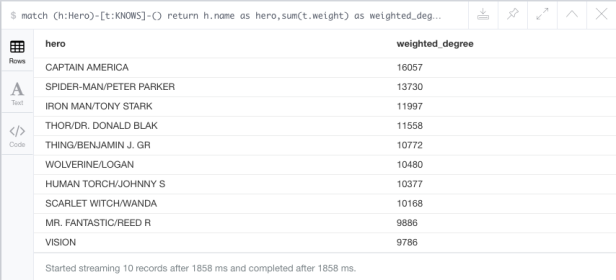
Heroes with top weighted degree:
We can check the heroes, that have the biggest weighted degree, which is just a sum of all weights of the relationships connected to given node.
Even though we treat our network as undirected, Neo4j still stores the relationships as directed. That is not a problem as we can MATCH without specifying direction of relationship, so we query it as undirected, where we do not care about the direction of relationship.
MATCH (h:Hero)-[t:KNOWS]-() RETURN h.name as hero,sum(t.weight) as weighted_degree ORDER BY weighted_degree DESC LIMIT 10
Results:
This is the first part, where we learned how to import a social graph and create a weighted undirected network between our heroes. Now we can start to test graph algorithms like neo4j graph algoritms or apoc graph algorithms on our network. Stay tuned as I will talk about algorithms more next time.

Thanks, Tomaž. Fun article. I hadn’t seen apoc.periodic.iterate before, and I have now I using it to perform post-processing relationship creation on a large graph. Extremely useful.
LikeLike
Quick question: “…that it checks if there is a relationship between given nodes in any direction, and if not found, it creates one in a random direction.” Should that read “… and if found, it creates one…
LikeLike
don’t think so… It checks if there exists a relationship between nodes. If there isn’t one yet (not found) it creates a relationship with property weight being 1. If found it increases relationship weight property by 1.
LikeLike
Understand now. Thanks
LikeLike
IT IS REALLY NICE to have real examples to follow, compared to the cryptic Neo4j cypher manual and other documentation….which all makes sense if you already know how to use it, but not for newbies…..
LikeLike
Nowadays i post to medium. Check the about site for link
LikeLike