This is the second part of GoT series, if you haven’t seen the first part, i suggest you check it out. In this part I will show you how I approach connecting different sources together in a knowledge graph.
Data:
We will be using kaggle dataset of Game of Thrones, which I saved on my github repo for easier access. In this second part we will import character_deaths.csv. It contains information about characters and when they died.
Graph model:

We will build on top of battles.csv from previous part. We will add Book,Status nodes and BELONGS_TO relationship from Person to a House.
Linking:
When dealing with real world data, we run into dirty data sooner or later. We have information about Person and House nodes in all three CSVs. Before importing the second CSV on top of the first one, I always check how well do they match and if there is anything I can do to improve it. I will show you an example of matching House nodes.
First I check how many rows in the CSV have row.Allegiances (name of the house) column non-null.
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/tomasonjo/neo4j-game-of-thrones/master/data/character-deaths.csv" as row return count(row.Allegiances)
We get back a result of 917 rows.
Then I check how many houses match to existing nodes. Using a MATCH in this case works like an INNER JOIN in SQL, where you only get back rows that match the first table on a specific property (node in our case).
LOAD CSV WITH HEADERS FROM
"https://raw.githubusercontent.com/tomasonjo/neo4j-game-of-thrones/master/data/character-deaths.csv" as row
MATCH (h:House{name:row.Allegiances})
return count(row.Allegiances)
We get back a result of 414 rows. So the remainder did not match. There are two options. First one is there are new Houses in the second CSV, that did not appear in the first CSV, or there is a slightly different record of the same houses (typos etc…) in the second CSV.
After inspecting the data I noticed that sometimes the record of row.Allegiances is “Stark”, and other times it is “House Stark”. Here lies our problem, that some row.Allegiances do not match existing House nodes. We can check how removing the “House ” from the value will affect our linking data.
LOAD CSV WITH HEADERS FROM
"https://raw.githubusercontent.com/tomasonjo/neo4j-game-of-thrones/master/data/character-deaths.csv" as row
// use a replace function to remove "House "
MATCH (h:House{name:replace(row.Allegiances,"House ","")})
return count(row.Allegiances)
We get back a result of 521 rows, which is a slight improvement. This is how I generally approach linking different sources. Checking at raw data and trying different things to see what works best. Once you find the best solution (you might also fix raw data), then you can import the data, so that it fits our existing graph as good as possible.
MATCH statement used as above works as an INNER JOIN, where we could only update existing nodes if we wanted or just count them. On the other hand MERGE in this context works as an OUTER JOIN in SQL, where we combine different persons from two sources into a single graph.
I did something similar for Person node and corrected a few names in the CSVs.
Import:
Once we are done with linking the data, we can import it into Neo4j. The character_deaths.csv is not so complicated, so we can import in a single query. You will notice that parts of queries repeat from the first one. I hope by the end of this series you will be able to import any csv, as this are mainly all the things you need to know when importing into Neo4j. I will also show you how to use a CASE statement.
LOAD CSV WITH HEADERS FROM
"https://raw.githubusercontent.com/tomasonjo/neo4j-game-of-thrones/master/data/character-deaths.csv" as row
// we can use CASE in a WITH statement
with row,
case when row.Nobility = "1" then "Noble" else "Commoner" end as status_value
// as seen above we remove "House " for better linking
MERGE (house:House{name:replace(row.Allegiances,"House ","")})
MERGE (person:Person{name:row.Name})
// we can also use CASE statement inline
SET person.gender = case when row.Gender = "1" then "male" else "female" end,
person.book_intro_chapter = row.`Book Intro Chapter`,
person.book_death_chapter = row.`Death Chapter`,
person.death_year = toINT(row.`Death Year`)
MERGE (person)-[:BELONGS_TO]->(house)
MERGE (status:Status{name:status_value})
MERGE (person)-[:HAS_STATUS]->(status)
// doing the foreach trick to skip null values
FOREACH
(ignoreMe IN CASE WHEN row.GoT = "1" THEN [1] ELSE [] END |
MERGE (book1:Book{sequence:1})
ON CREATE SET book1.name = "Game of thrones"
MERGE (person)-[:APPEARED_IN]->(book1))
FOREACH
(ignoreMe IN CASE WHEN row.CoK = "1" THEN [1] ELSE [] END |
MERGE (book2:Book{sequence:2})
ON CREATE SET book2.name = "Clash of kings"
MERGE (person)-[:APPEARED_IN]->(book2))
FOREACH
(ignoreMe IN CASE WHEN row.SoS = "1" THEN [1] ELSE [] END |
MERGE (book3:Book{sequence:3})
ON CREATE SET book3.name = "Storm of swords"
MERGE (person)-[:APPEARED_IN]->(book3))
FOREACH
(ignoreMe IN CASE WHEN row.FfC = "1" THEN [1] ELSE [] END |
MERGE (book4:Book{sequence:4})
ON CREATE SET book4.name = "Feast for crows"
MERGE (person)-[:APPEARED_IN]->(book4))
FOREACH
(ignoreMe IN CASE WHEN row.DwD = "1" THEN [1] ELSE [] END |
MERGE (book5:Book{sequence:5})
ON CREATE SET book5.name = "Dance with dragons"
MERGE (person)-[:APPEARED_IN]->(book5))
FOREACH
(ignoreMe IN CASE WHEN row.`Book of Death` is not null THEN [1] ELSE [] END |
MERGE (book:Book{sequence:toInt(row.`Book of Death`)})
MERGE (person)-[:DIED_IN]->(book))
Conclusion:
We have successfuly imported second CSV of the dataset. There is only one left to import and then we can start to play around with analysing dataset and visualizing it with spoon.js
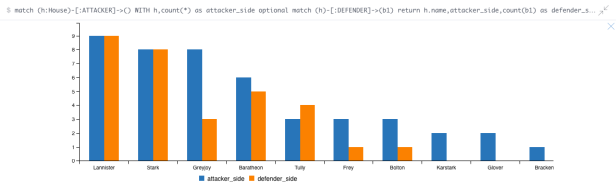
Example visualization:
How many battles did each house participate in either as attacker or defender ?
match (h:House)-[:ATTACKER]->() WITH h,count(*) as attacker_side optional match (h)-[:DEFENDER]->(b1) return h.name,attacker_side,count(b1) as defender_side order by attacker_side desc limit 10