
This is part 2 of Marvel series. In previous post I imported the data from kaggle competition and showed how to project a mono-partite graph from a bipartite graph. We used a topological similarity measure, that takes into account how many common comics any pair of heroes have.
For easier understanding we can represent this as the following function:
(:Hero)←(:Comic)→(:Hero)
to
(:Hero)←[:KNOWS{weight=Nb of Common Comics}]→(:Hero)
To find out more check this Gephi tutorial. We could have also projected mono-partite graph looking like:
(:Comic)←[{weight=Nb of Common Heroes}]→(:Comic)
You will need to have the graph imported to proceed with the following steps in analysis.
Requirements:
- Neo4j — Neo4j Site
- Graph algorithms — Graph algorithms plugin
- Apoc plugin — Apoc plugin
Graph model:

We end up with a simple graph model. We started with a bi-partite(two types/labels of nodes) network of Heroes and Comics and then inferred a mono-partite (single type/label of nodes) graph amongst Heroes based on the number of common Comics.
Analysis
We will analyse the inferred network of Heroes. I usually start with some global statistics to get a sense of the whole graph and then dive deeper.
Weight distribution
First we check the distribution of similarity weights between pairs of heroes. Weight value translates to the number of common Comics Heroes have appeared in.
MATCH ()-[k:KNOWS]->() RETURN (k.weight / 10) * 10 as weight,count(*) as count ORDER BY count DESC LIMIT 20
You might wonder why we use (k.weight / 10) * 10 as it looks silly at first glance. If we divide an integer by an integer in Neo4j we get back integer. I use it as an bucketizing function,that groups numeric data into bins of 10, so that it is easier to read results.
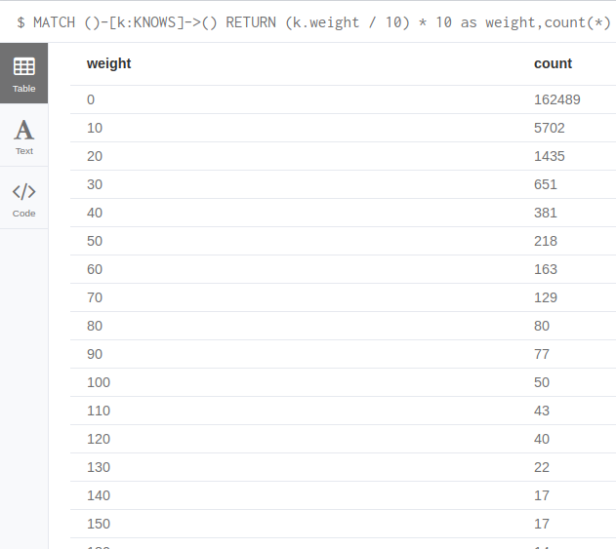
162489 out of total 171644 relationships (94%) in our network has weight 9 or less. This means that most of our Heroes have only briefly met.
Largest weight is between “THING/BENJAMIN J. GR” and “HUMAN TORCH/JOHNNY S” at value 724. I would assume they are good buddies.
Even though we have a well connected graph, most of relationships are “weak” judging by weight. I would assume that most comics have standard teams of heroes, where not necessarily all of the team appear in every comic.
Second assumption I would make is that there are occasinal comics where different “teams” of heroes appear in together, hence so many weak relationships.
To check my assumptions I start with this query to get a basic feel.
MATCH (u:Comic) RETURN avg(apoc.node.degree(u,'APPEARED_IN')) as average_heroes, stdev(apoc.node.degree(u,'APPEARED_IN')) as stdev_heroes, max(apoc.node.degree(u,'APPEARED_IN')) as max_heroes, min(apoc.node.degree(u,'APPEARED_IN')) as min_heroes

I personally prefer distribution over average. We use the “bucketizing” function as before:
MATCH (u:Comic) RETURN (size((u)-[:APPEARED_IN]-()) / 10) * 10 as heroCount, count(*) as times ORDER BY times DESC limit 20
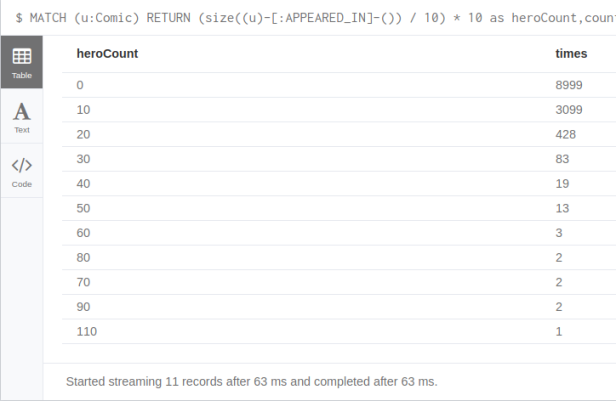
Looks like my assumptions are plausible and quite possible. 8999 (71%) of comics have less than 10 heroes playing, with most of them probably at around 5 or less as the total average is 7,5. There are a few comics where we have “family gatherings” with more than 30 heroes. One of them is a comic named COC1, probably Contest of Champions, where 110 heroes play.
Normalize weight:
If we need to, we can normalize the weight using min-max method.
Notice how this time we use (toFloat(k1.weight) - min) / (max - min). By declaring k.weight a float, we are dividing a float by an integer, that returns a float and does not bucketize/group number into bins
MATCH (:Hero)-[k:KNOWS]->(:Hero) //get the the max and min value WITH max(k.weight) as max,min(k.weight) as min MATCH (:Hero)-[k1:KNOWS]->(:Hero) //normalize SET k1.weight_minmax = (toFloat(k1.weight) - min) / (max - min)
Triangle count / Clustering coefficient
In graph theory, a clustering coefficient is a measure of the degree to which nodes in a graph tend to cluster together. Evidence suggests that in most real-world networks, and in particular social networks, nodes tend to create tightly knit groups characterised by a relatively high density of ties; this likelihood tends to be greater than the average probability of a tie randomly established between two nodes (Holland and Leinhardt, 1971;[1] Watts and Strogatz, 1998[2]).
Two versions of this measure exist: the global and the local. The global version was designed to give an overall indication of the clustering in the network, whereas the local gives an indication of the embeddedness of single nodes.[1]
CALL algo.triangleCount('Hero', 'KNOWS',
{write:true, writeProperty:'triangles',
clusteringCoefficientProperty:'coefficient'})
YIELD nodeCount, triangleCount, averageClusteringCoefficient;
Running this algorithms writes back local triangle count and clustering coefficient, while providing total triangle count and average clustering coefficient of the graph as return.
Find out more in documentation.

Average clustering is very high at 0.77, considering that 1 would mean we have a complete graph, where everybody knows each other. This comes as no surprise as we observed before that our network is very connected with most of relationships being “weak”.
Connected Components
Testing whether a graph is connected is an essential preprocessing step for every graph algorithm. Such tests can be performed so quickly and easily that you should always verify that your input graph is connected, even when you know it has to be. Subtle, difficult-to-detect bugs can result when your algorithm on a disconnected graph.
Connected components have other practical use cases, for example, if we are analysing a social network and we want to find all the disconnected groups of people that exist in our graph.
More in documentation.
CALL algo.unionFind.stream('Hero', 'KNOWS', {})
YIELD nodeId,setId
WITH setId,count(*) as communitySize
// filter our single node communities
WHERE communitySize > 1
RETURN setId,communitySize
ORDER BY communitySize DESC LIMIT 20

Our graph consists of 22 total components with the largest covering almost all the graph(99,5%). There is 18 single node communities, and 3 very small ones with 9, 7 and 2 members.
Lets check who are the members of these small components.
CALL algo.unionFind.stream('Hero', 'KNOWS', {})
YIELD nodeId,setId
WITH setId,collect(nodeId) as membersId,count(*) as communitySize
// skip the largest component
ORDER BY communitySize DESC SKIP 1 LIMIT 20
MATCH (h:Hero) WHERE id(h) in membersId
RETURN setId,collect(h.name) as members
ORDER BY length(members) DESC
We need to match nodes by their nodeId from result so that we can get back the names of heroes.

18 heroes never appeared in a comic with any other heroes. Some of the are RED WOLF II, RUNE, DEATHCHARGE etc. Second largest component with 9 members seems to be the ASHER family and some of their friends.
Weighted Connected Components
What if decided that two heroes co-appearing in a single comic is not enough of interaction for us to tag them as colleagues and raise the bar to 10 common comics.Here is where weighted Connected Component algorithm can help us.
If we define the property that holds the weight(weightProperty) and the threshold,it means the nodes are only connected, if the threshold on the weight of the relationship is high enough otherwise the relationship is thrown away.
In our case it means that two heroes need at least 10 common comics to be considered connected.
CALL algo.unionFind.stream('Hero', 'KNOWS',
{weightProperty:'weight', threshold:10.0})
YIELD nodeId,setId
RETURN setId,count(*) as communitySize
ORDER BY communitySize DESC LIMIT 20;
Define weightProperty and threshold.

As we could expect the biggest component drops significantly in size from 99,5% to 18,6% of total number of nodes. Using threshold can be used to find potentially resilient teams of heroes as more interactions between heroes (we take any co-appearance as positive) means longer history and more bonding, which can translate to resilience.
We can play around with different threshold settings.
Not only community sizes are interesting, but also their members. We check the members of the largest communities skipping the first one as showing 1200 names in a browser can be messy.
CALL algo.unionFind.stream('Hero', 'KNOWS',
{weightProperty:'weight', defaultValue:0.0, threshold:10.0})
YIELD nodeId,setId
WITH setId,collect(nodeId) as membersId,count(*) as communitySize
// skip the largest component
ORDER BY communitySize DESC SKIP 1 LIMIT 20
MATCH (h:Hero) WHERE id(h) in membersId
RETURN setId,collect(h.name) as members
ORDER BY length(members) DESC

Second largest community has really cool names like Bodybag,China Doll and Scatter Brain. As I have no clue of the domain I can’t really give any other comment.
Conclusion:
While this post is long, it does not contain everything I want to show on Marvel graph, so there will be one more post using centralities with cypher loading and maybe some community detection with Louvain and Label Propagation Algorithm.
Hope you learned something today!
Reference:
[1] https://en.wikipedia.org/wiki/Clustering_coefficient
